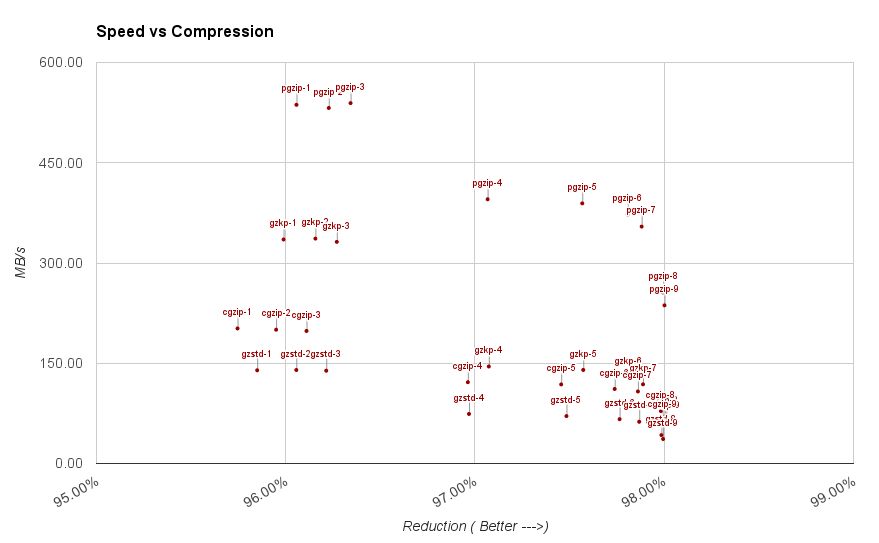
As a continuation of my release of a Optimized gzip/zip packages. I have done some informal benchmarks to get an impression of performance characteristics of the various libraries. I have compiled the results in a spreadsheet you can view yourself.
Update (18 Sept 2015): Level 1 compression has been updated to a faster version, so the difference to deflate level 1 has gotten smaller. The benchmark sheet has been updated, so some of these numbers may be inaccurate.
This is not a formal benchmark. My computers all have Speedstep and Turbo boost functionality, which makes benchmarks a little unreliable, but it should be good enough to give a general impression. You should also note that this shows performance for large datasets, where initialization and memory imprint doesn’t show. If you are interested in performance for small files less than 1KB, this doesn’t give information on how that will perform.
I revised a benchmark program written by Arne Hormann. You can see/download the benchmark program here.
Standard library gzip
The Go standard library gzip is almost always slowest at any given level. It does however in a few cases have a very slight compression advantage with medium compressible content. This is most likely because it can do length-3 matches.
On highly compressible content it is a disadvantage to make 3 byte matches, because the Huffman-compressed literals are likely shorter than coding the match. However with material that is harder to compress the 3 literal bytes take more bits than coding a back-reference.
Recommendation: Use only if you know you don’t have SSE 4.2 or cgo available. Never use a level smaller than 3, since it is just as fast and compresses better.
cgzip package
cgzip wraps zlib using cgo. cgzip has worse compression in almost all scenarios at a given compression level. When comparing, it almost seems to make sense to assume that cgzip at level x compares to level x+1 with other compressors.
Speedwise it ties, or is slightly behind the revised libraries on content that is easy to compress. Once the content gets harder to compress it pulls slightly about 20% ahead of the revised libraries, but always with worse compression.
With content that is impossible to compress it is about 70% faster.
Recommendation: Use only for uncompressible data (and what is the point in that?) I wouldn’t recommend it anyway, since it requires a cgo setup which complicates use. It may still be better for small payloads, which I will benchmark next.
Revised gzip package
My revised gzip package is always faster for highly compressible data and compresses better. Even in the worst case scenarios it is never more than 1% slower and never more than 1% worse compression than standard library.
It seems to be a lot more resilient to hash collisions, so the slowdown on medium compressible data isn’t nearly as big as with the standard library.
Recommendation: Use for all high compression (HTML/XML/JSON, CSS, JS, etc) compression. Generally safe to use instead of the standard library.
pgzip package
pgzip is not meant as a general-purpose gzip, but rather when you have big amounts of data. Since it processes blocks in parallel it obviously has a speed advantage on the other compressors.
An interesting aspect is that it compresses better than any other compressors at level 1-3. The reason for this is that at levels 1-3 one of the things the compressor does to speed things up is to skip hashing of intermediate values when a long match is made. Since the compressor is re-initialized at regular intervals with pgzip, these values actually gets hashed and matches can be made with these.
Recommendation: Use for high throughput, high compression material, like logs, json, csv data. Never use on input smaller than 1MB. Above level 5 there is only a small compression gain, so use at level 5 or lower.
Overall points – future work
I was quite surprised on the massive slowdown on medium-compressible material. At compression levels higher than 6 you dip below 10MB/s down to 3MB/s very quickly. This is potentially a problem, since it can lead to unexpected slowdowns. So this is definitely something to be aware of. It seems the revised library performs much better in these cases due to the improved hash algorithm. However, the large differences in performance it something that should be looked at. The issue that it is SO much slower, with so little gained compression should be looked at.
It could be interesting to investigate is to make an adaptive mode that attempts to always keep above a certain speed, no matter what the compression ration cost will be. I doubt a pre-compression classifier can be made really well (though zpaq has a good, but not amazingly fast one), but maybe there could be some internal monitoring in the compression function, that disables parts of the compression, if a section is too slow to compress.
I might also investigate a very lightweight deflater, that will have much worse compression, but be very, very fast. This could be a good thing where using gzip on a server proves too costly in terms of CPU, but you would still like to save 50% bandwidth.
That is all I have for now. You Follow me on Twitter for more updates.
Update: I have just added an article on Gzip Performance for Go Webservers.