After looking at some rare poor performance in rclone, I have created a package for read-ahead functionality, which I have implemented a few times in different contexts. This gave me the opportunity to create a solid implementation with solid tests to make sure it works with good performance.
For the impatient here is the package: https://github.com/klauspost/readahead
Use Case
Lets take an example where you are reading a file, decompressing and decoding it before you insert it into your database:
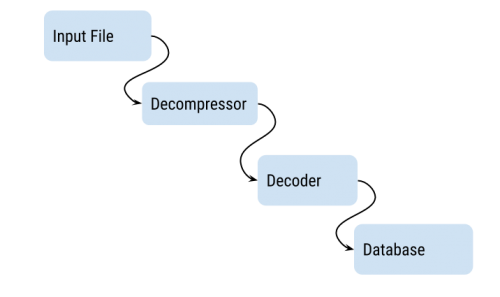
When you run it, you are likely to experience that you will max out 1 CPU, and that is capping your speed. When you profile your program you see that the decoder and the decompressor takes approximately the same amount of CPU time. So the natural thing to do is to split the decompressor and decoder into two separate goroutines. This is what readhead does for you:
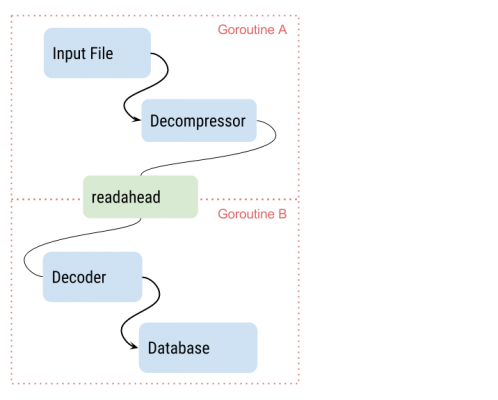
Now the decompressor and decoder are running concurrently. You may also find that the decompressor isn’t fully efficient because it has to wait for disk IO. In that case you can insert another readahead. However, as with all good things, don’t insert it if you don’t need to.
Let’s look at an example that matches the illustration above. Error handling is omitted:
// Open input
input, _ := os.Open("input.csv.gz")
unz, _ := gzip.NewReader(input)
// Create a Reader with default settings
ra := readahead.NewReader(unz)
defer ra.Close()
// Read all records and store them
r := csv.NewDecoder(ra)
for {
record, err := r.Read()
if err == io.EOF {
break
}
StoreDB(record)
}
So in effect, it is just as easy as to use as a bufio.Reader, and it will also server the same function, since it will read 1MB at the time with default settings. If 1MB is a lot for your use case, you can use the NewReaderSize(rd io.Reader, buffers, size int) to adjust the buffer size, as well as the maximum number of buffers to read ahead.
While writing this a few this came up. While the Read(p []byte) (n int, err error) interface might seem trivial, there are some things that comes up. First of all you can encounter return values like this: n > 0 && err !=nil && err != io.EOF which indicates an error, but that some data was read. The readahead package returns these values as-is.
Another thing is that some packages might return a specific error to indicate a temporary error, like a timeout, and hint that you should try again. The readahead code does NOT allow you to try again, and it will keep returning the same error if you try to read from it again.
This is consistent with how some of the standard packages behave. If you are dealing with an input that returns intermittent errors, but wants you to try again, you should wrap it in your own retry code, so these are caught before this filter. I will leave it to someone else to create a “retryreader” package.
Finally, there is the case where the input reader does not deliver as many bytes as we request. That is fairly common, and can indicate a lot of things. But to keep input->output latency at a minimum we forward this to output at once, even though you might have requested bigger buffers.
I hope this package will be helpful for you. If I have overlooked your implementation of a similar package, please leave a comment. I’d love to see alternative implementations, that may different uses.