This post will introduce the concept of deduplication and a Go package I have written to help you implement it. It is inspired by the work on the zpaq journaling archiver done by Matt Mahoney. If you are looking for a pure commandline tool, I can also recommend SuperRep by Bulat Ziganshin. This will however provide you with a streaming/indexed format you can use in your own Go programs.
For the impatient, you can find the package here: https://github.com/klauspost/dedup
What is deduplication?
Deduplication divides an input into blocks, creates a hash for each of them. If it re-encounters a block with the same hash, it simply inserts a reference to the previous block. If you consider an input, it will look like this:
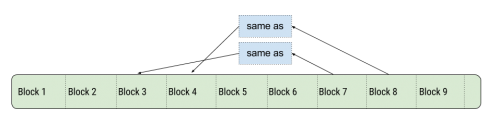
While this may sound like ordinary compression, it has some key differences. First of all, only complete blocks are checked. In compression like deflate, snappy, etc, you are looking for matches for each individual byte, in a limited window, for example 32KB-1MB. Deduplication will work across gigabytes and even terabytes of data, since it only needs to store a hash for each block.
The main downside is that data will only be deduplicated if the complete block matches. In contrast to compression, you will not get references to partial data inside the block. However, the speed difference to ordinary compression is significant, and with fixed block sizes you can expect more than 1GB/s to be deduplicated with fixed block sizes.
In fact it is often a good idea to compress the deduplicated output, since the original input of the original file is kept as-is. That means you still get good compression, but have to compress less data, giving you overall smaller output.
When should I use deduplication?

Deduplication will only give you an advantage if you expect there are duplicates. This is of course obvious, but lets list a few possible scenarios where that could occur. Of course duplicate data is unnecessary, but will happen unintentionally.
-
Hard disk images
This includes virtual machine images. You will often find duplicated data in harddisk images, since deleted files aren’t zeroed out. If you know the block size of your file system and deduplicate based on that size you will find a surprising amount of duplicate data.
-
Backup of data
Often when you do bulk backups you will have duplicate data in various places on your computer. It could be a copy of a database you’ve made, etc.
-
Data Synchronization
A lot of data streams that synchronize servers are more optimized for speed than size, so they are likely to have many duplicate entries.
Indexed or not?
If we look at the previous illustration, we can see how we can manage memory. When we are decoding, we keep block 3 & 4 in memory, until they have been written. This mean we can deallocate block like this when decoding:
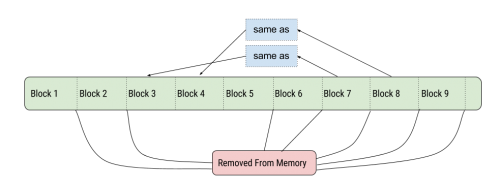
But, you may have noticed that for this to work we need to know in advance if we will need a block again. So, since we cannot predict the future, there is an index created that basically tells the decoder when it is ok to throw away a block. That is why there exists an indexed mode, which I strongly recommend you use if possible.
The non-indexed mode must have a maximum decoder RAM specified when encoding. Since it doesn’t know if a block will be used in the future, it will simply keep the number of blocks in memory that it is allowed to. This is of course sub-optimal compared to the indexed mode.
A third option when decoding is to use a `NewSeekReader`. This will never keep any blocks in memory, but will instead need to be able to seek on the input content. To determine if you should use a SeekReader, you can use `MaxMem()` once the index has been parsed to get the real memory usage. If it is too high, you can simple use a NewSeekReader instead of a NewReader.
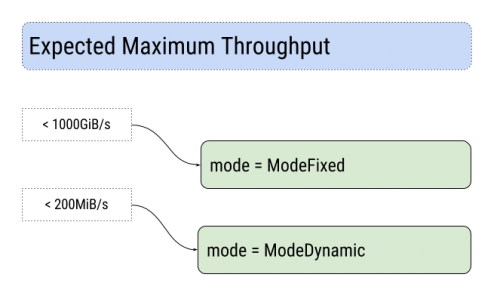
To simplify your choice when encoding I have made this chart:

Block types and sizes
There are two types of blocks: Fixed Size blocks all have the same size, or Dynamic blocks which have a variable size. “Fixed size” blocks are easier to deal with in terms of memory use and are significantly faster. Dynamic blocks offer better deduplication.
The maximum size of each block can also be adjusted. Smaller block sizes typically offer better deduplication, but are a little slower and add indexing overhead. So again you have to adjust to your input. On a decent machine, you can use the following chart to make your choice:
As a further refinement you can specify block splits yourself. If you are writing blocks to the stream, you can call the `Split()`function to indicate a block split. This will end the current block and start a new one.
Setting the maximum memory
In general the performance characteristics of the deduplicator looks like this:

The “encoding” side is CPU limited, and occupied with splitting blocks, creating and checking hashes. The output is limited mainly by memory or IO, if the seeking decoding is used. The tricky part is that when you encode your content, you also set the amount of memory needed for the decoder. However, there are some factors that will usually make the decoder use way less memory than the maximum you specify.
When you use indexed mode, it is possible to de-allocate memory early. In reality, this means that if there are few matches, or they are very close, you will likely only use 10% of the memory you allow. If you use dynamic sized blocks, remember that the average block size is around 25% of the maximum block size – however, to be safe we assume that all blocks are at their maximum size.
This could help you select a reasonable maximum memory setting based on the maximum RAM you have available on your decoder.
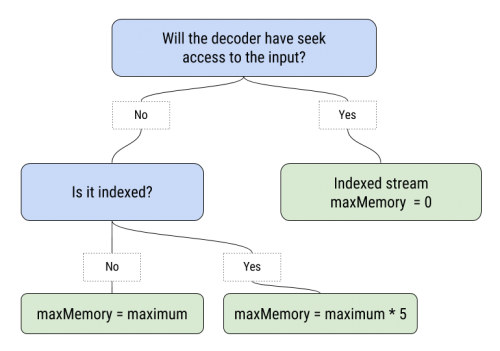
The factor 5 depends on a lot of things, but should be fairly safe in most circumstances. Remember that if you use dynamic blocks, you can multiply the maxMemory with 3, and still be on the reasonably safe side.
Some numbers
This should give you an idea of what you can expect as base performance. The benchmarks show performance of various block sizes on a desktop “Intel Core i7 2600 @3.4Ghz, Quadcore”. Go run the benchmark, go to the package directory and run go test -bench=.
BenchmarkReader64K-8 3000 2789159 ns/op 3759.47 MB/s BenchmarkReader4K-8 2000 4723270 ns/op 2220.02 MB/s BenchmarkReader1K-8 1000 9382536 ns/op 1117.58 MB/s BenchmarkReaderStream64K-8 300 4236909 ns/op 2474.86 MB/s BenchmarkReaderStream4K-8 300 6017010 ns/op 1742.69 MB/s BenchmarkReaderStream1K-8 100 11000629 ns/op 953.20 MB/s BenchmarkFixedWriter64K-8 1000 8809503 ns/op 1190.28 MB/s BenchmarkFixedWriter4K-8 1000 10712612 ns/op 978.82 MB/s BenchmarkFixedWriter1K-8 500 14862850 ns/op 705.50 MB/s BenchmarkDynamicWriter64K-8 100 51222930 ns/op 204.71 MB/s BenchmarkDynamicWriter4K-8 100 56213215 ns/op 186.54 MB/s BenchmarkFixedStreamWriter4K-8 1000 10730613 ns/op 977.18 MB/s
This is the raw performance of the package itself. However, to show a bit more “real-world” performance and gains, I have made a simple test, where I deduplicated and compressed a virtual machine disk image. The tables below shows the combined speed and achieved compression with different deduplication settings. This is not a professionally performed benchmark, and should only be taken as an indication, of how it could perform.
Test 1, Indexed
A “.tar” of a Virtual Disk image, Linux Mint 14 with dev tools installed ~8GB in size. The disk image is deduplicated with index and both are compressed with pgzip level 1. Test is performed on a desktop “Intel Core i7 2600 @3.4Ghz, Quadcore”. All the fixed sized tests are SSD read speed limited.
| Block Type | Max Block Size | Decode mem | Deduplicated | Gzipped | Index | Speed | Size |
| None | – | – | 7.97GB | 3.67GB | 0.00GB | 237MB/s | 46.05% |
| Fixed | 4096 | 89.60MB | 6.95GB | 3.30GB | 0.00GB | 233MB/s | 41.41% |
| Fixed | 1024 | 244.51MB | 6.06GB | 3.10GB | 0.00GB | 228MB/s | 38.94% |
| Fixed | 512 | 674.48MB | 5.19GB | 2.58GB | 0.00GB | 222MB/s | 32.40% |
| Dynamic | 16384 (4428) | 673.36MB | 5.67GB | 2.54GB | 0.00GB | 142MB/s | 31.96% |
| Dynamic | 4096 (689) | 685.87MB | 4.92GB | 2.42GB | 0.01GB | 124MB/s | 30.55% |
| Dynamic | 1024 (238) | 691.86MB | 4.60GB | 2.35GB | 0.03GB | 103MB/s | 29.89% |
The average block size is noted after the max block size. Decode memory is the actual amount of memory that will be used for decoding.
The conclusion to draw from this seems to be that a fixed block size of 512 bytes seems to give the best compression/performance. With that, we save 1 GB of the total size, and we will need 700MB to decode it.
Test 2, Streamed
A Virtual Disk image, Boot2Docker, used for various builds, 11.5GB in size. The disk image is deduplicated with no index and compressed with pgzip level 1. Test is performed on a laptop “Intel Core i5 2540M @2.6Ghz, Dual core”.
For the dynamic blocksizes, the average blocksizes are noted after the max block size, and the actual maximum memory is also written in parenthesis. The *actual* memory use will never be above the deduplicated stream size, in this case 11.5GB.
| Block Type | Max Block Size | Max Memory | Deduplicated | Gzipped | Speed | Size |
| None | – | – | 11.54GB | 6.07GB | 124MB/s | 52.56% |
| Fixed | 4096 | 16GB | 6.30GB | 2.47GB | 149MB/s | 21.38% |
| Fixed | 1024 | 16GB | 5.99GB | 2.43GB | 110MB/s | 21.09% |
| Fixed | 4096 | 4GB | 6.61GB | 2.59GB | 136MB/s | 22.41% |
| Fixed | 1024 | 4GB | 6.27GB | 2.55GB | 108MB/s | 22.12% |
| Fixed | 4096 | 1GB | 7.59GB | 2.99GB | 136MB/s | 25.94% |
| Fixed | 1024 | 1GB | 7.23GB | 2.97GB | 108MB/s | 25.74% |
| Dynamic | 16384 (4364) | 64GB (17.0GB) | 5.65GB | 2.28GB | 84MB/s | 19.74% |
| Dynamic | 4096 (839) | 64GB (13.9GB) | 5.10GB | 2.19GB | 70MB/s | 18.95% |
| Dynamic | 16384 (4364) | 16GB (4.25GB) | 5.81GB | 2.34GB | 82MB/s | 20.26% |
| Dynamic | 4096 (839) | 16GB (3.47GB) | 5.62GB | 2.41GB | 68MB/s | 20.85% |
| Dynamic | 16384 (4364) | 4GB (1.06GB) | 6.77GB | 2.73GB | 88MB/s | 23.62% |
| Dynamic | 4096 (839) | 4GB (0.86GB) | 6.38GB | 2.76GB | 88MB/s | 23.94% |
Here we see a similar image. Overall, the disk image size is reduced with 50%, even at moderate settings, and the speed is even increased with fixed block sizes, since the compressor has less data to compress.
The block sizes have a small effect, and lowering it from 4K to 1K gives only a small improvement. The most significant effect is the allowed memory usage, with the step from 4GB down to 1GB giving the biggest difference. The difference between 4GB and “unlimited” (16GB) memory is surprisingly small.
Future Development
This is a base package, but with the current format it is possible to extend functionality in the future. Possible new features are:
Output raw blocks
An option that should be available soon will be to output raw blocks, so you can use the deduplicator to split blocks for you, and you can insert them into a key-value based DB.
Stream merging
It is possible to merge two streams as a single stream with or without deduplication across boundaries. If there has to be effective deduplication across boundaries the streams would have to be created with similar settings, and they would need to be re-hashed. However, both options are valid, and could be possible in the future.
Memory limit indexed streams
It would be possible to impose a memory limit on indexed streams, by re-writing them. They would become a bit bigger, but since they are already indexed, it would be possible to only duplicate blocks with the least amount of references and distance between them.
Collision safe streams
It would be possible to make streams collisions safe, by storing the actual bytes of block in memory and compare them when deduplicating. It would however be very RAM consuming, so unless someone has a use case, where a stronger hash doesn’t help them, this is not something I currently plan to implement.
If you have any features you see as a natural extension of this package, or you would like me to hurry with one of the listed ones, feel free to leave a comment below, or add an issue on the github page.